| commit | 73f638711aebe0d571b2ca30357f972e6552749d | [log] [tgz] |
|---|---|---|
| author | Android Build Coastguard Worker <[email protected]> | Fri Jul 07 04:52:37 2023 +0000 |
| committer | Android Build Coastguard Worker <[email protected]> | Fri Jul 07 04:52:37 2023 +0000 |
| tree | 1777676381e03535f9ddb10e2bcdda7c67d90903 | |
| parent | b7468854e2c76ef323b094981e96c2b70cd5d8ab [diff] | |
| parent | 656c1fb4b3ebd7cff07a8dff49019d703a1e5aba [diff] |
Snap for 10453563 from 656c1fb4b3ebd7cff07a8dff49019d703a1e5aba to mainline-documentsui-release Change-Id: Id90f8a1153019482381a664782b5900a5a099b6c
Pure Rust implementation of Ryū, an algorithm to quickly convert floating point numbers to decimal strings.
The PLDI'18 paper Ryū: fast float-to-string conversion by Ulf Adams includes a complete correctness proof of the algorithm. The paper is available under the creative commons CC-BY-SA license.
This Rust implementation is a line-by-line port of Ulf Adams' implementation in C, https://github.com/ulfjack/ryu.
Requirements: this crate supports any compiler version back to rustc 1.36; it uses nothing from the Rust standard library so is usable from no_std crates.
[dependencies] ryu = "1.0"
fn main() { let mut buffer = ryu::Buffer::new(); let printed = buffer.format(1.234); assert_eq!(printed, "1.234"); }
You can run upstream's benchmarks with:
$ git clone https://github.com/ulfjack/ryu c-ryu $ cd c-ryu $ bazel run -c opt //ryu/benchmark:ryu_benchmark
And the same benchmark against our implementation with:
$ git clone https://github.com/dtolnay/ryu rust-ryu $ cd rust-ryu $ cargo run --example upstream_benchmark --release
These benchmarks measure the average time to print a 32-bit float and average time to print a 64-bit float, where the inputs are distributed as uniform random bit patterns 32 and 64 bits wide.
The upstream C code, the unsafe direct Rust port, and the safe pretty Rust API all perform the same, taking around 21 nanoseconds to format a 32-bit float and 31 nanoseconds to format a 64-bit float.
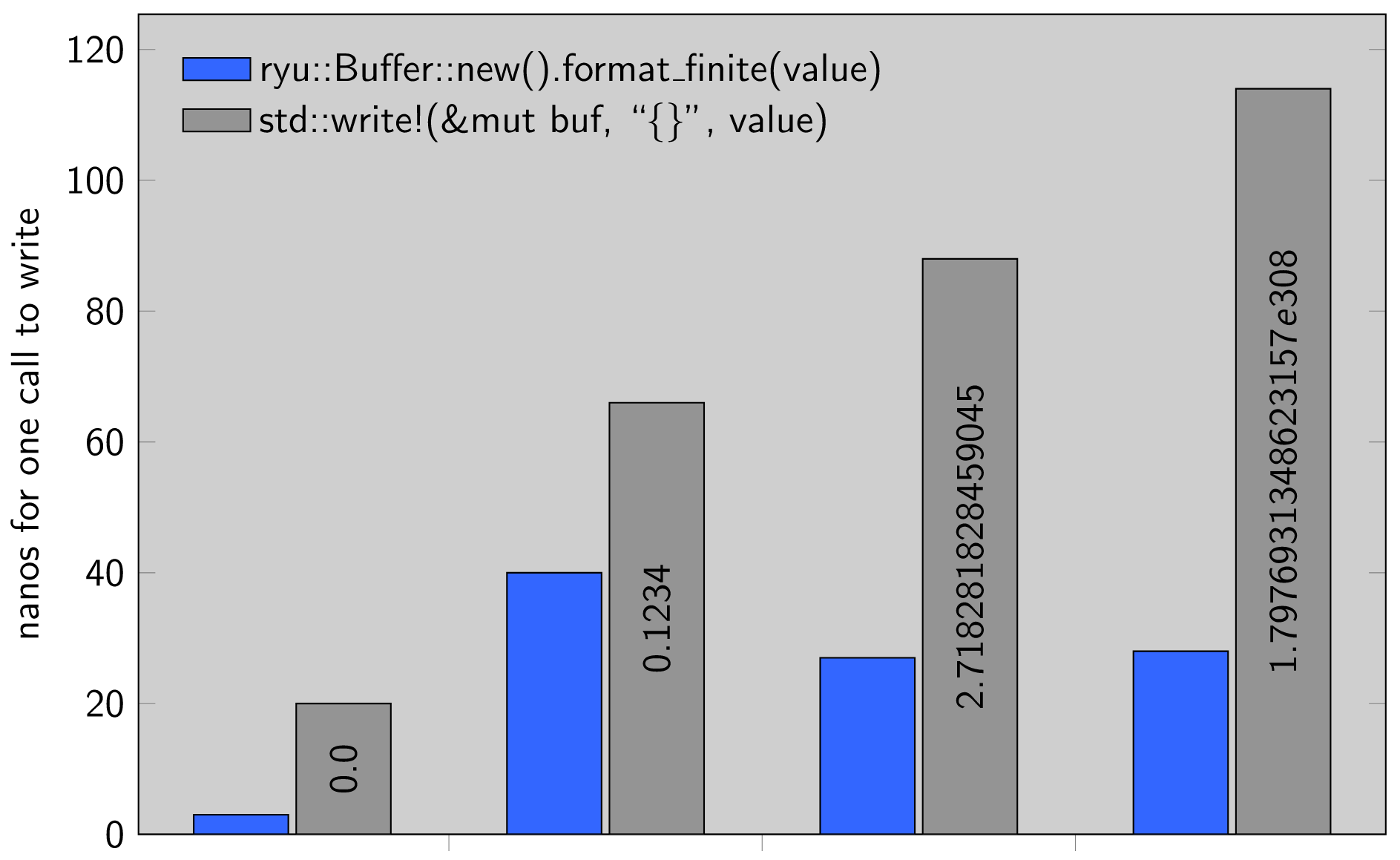
There is also a Rust-specific benchmark comparing this implementation to the standard library which you can run with:
$ cargo bench
The benchmark shows Ryū approximately 2-5x faster than the standard library across a range of f32 and f64 inputs. Measurements are in nanoseconds per iteration; smaller is better.
This library tends to produce more human-readable output than the standard library's to_string, which never uses scientific notation. Here are two examples:
Both libraries print short decimals such as 0.0000123 without scientific notation.